: 聊一聊垃圾回收机制吧。
: 恩,垃圾回收是自动的。
基本概念
GC(Garbage collection)垃圾回收机制。目的是解释器去判别需要回收的内容,当解释器认为一个占着房子的人已经没有存在的意义了,就自动收回房子重新对外出租(available)。JS和PY都选择不相信程序员,选择自己操控内存问题。
Node的对象都是分配在堆内存上,V8主要把内存分为 new-space 和 old-space ,64位系统对应的大小约为 32MB 和 1400MB(32位系统对应折半)。二者共同构成Node的总内存(约为1.4G)。
新生代空间的对象生存周期比较短,容量也比较小,老生代的对象都是“强硬派”,生命力旺盛,容量比较大。Node 不是 HipHop 为啥非要把内存分这个 “new-school”,“old-school” ?,就是因为在实际的情况中,各种垃圾回收策略并不能满足解决不同的对象声明周期长短不一的问题,而只是针对某一种特定情况非常有用,所以基于分代策略能够根据对象的生命周期不同,采用最适合的算法策略进行高效垃圾回收。
Node对两个不同生代的不同垃圾回收策略构成了整个Node的垃圾回收机制。下面就来详细说明这两个不同的生代究竟是怎么处理的辣鸡的。
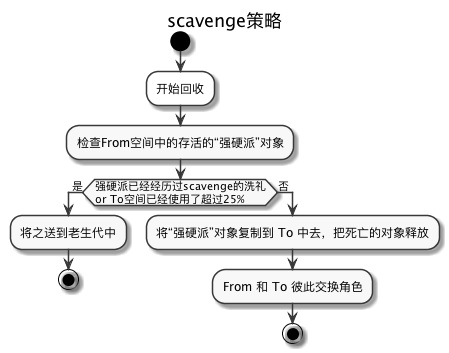
new-space 与 Scavenge算法
回顾一下 new-space 的特点:对象的生存周期普遍都比较短。这意味着,“老革命”对象比较少
Scavenge 策略把 new-space 一分为两个 “simispace”(半空间),一个叫 处于使用状态的 From 空间 一个叫闲置的 TO 空间。整个回收的过程就是如下图:
引用计数与闭包
那么在新生代中如何让GC知道某一个对象已经没有价值即该对象的生命周期已经结束了呢?
引用计数:所谓引用计数就是跟踪并记录每一个值被引用的次数,当我们生命了一个变量并且将一个引用类型赋值给该变量,那么该引用对象的引用计数加一,如果同一个变量又赋值给了另外一个变量,那么计数再一次增加1。那么相反的是如果某一个有引用类型值得变量又被赋了另外一个值,那么原先的引用类型的计数就相应的减一,或者当在一个函数执行完毕之后,该函数在执行时所创建的作用域将销毁,与此同时在该函数作用域中声明的局部变量所对应的内存空间的引用计数将随之减一,不出现闭包的情况下,下一次的垃圾回收机制在被触发的时候,作用域中的变量所对应的空间就会结束声明周期。像下面的代码那样:
1 | function callOnce(){ |
那么所谓闭包,一个在面试中都快被问烂了的概念:),其实说白了就是运用函数可以作为参数或者返回值使得一个外部作用域想要访问内部作用域中的私有变量的一种方式
1 | function foo(){ |
上述代码就形成了一个闭包,使得一旦有了变量引用了foo函数的返回值函数,就使得该返回值函数得不到释放,也使得foo函数的作用域得不到释放,即内存也不会释放,除非不再有引用,才会逐步释放。
old-space 与 标记-清除/标记-整理
分代之中除了 new-space 之外即是 old-space 了 ,分代的目的是为了针对不同的对象生命周期运用不同的回收算法。
满足条件晋升到老生代的的对象都有着比较顽强的生机,意味着在老生代中,存活的对象占有者很大的比重,使用新生代基于复制的策略会有着比较差的效率,此外,新生代中一分为二的空间策略面对着存活对象较多的情况也比较不合适。所以在老生代中V8采用了标记-清除与标记-整理这这两种方式结合的策略。
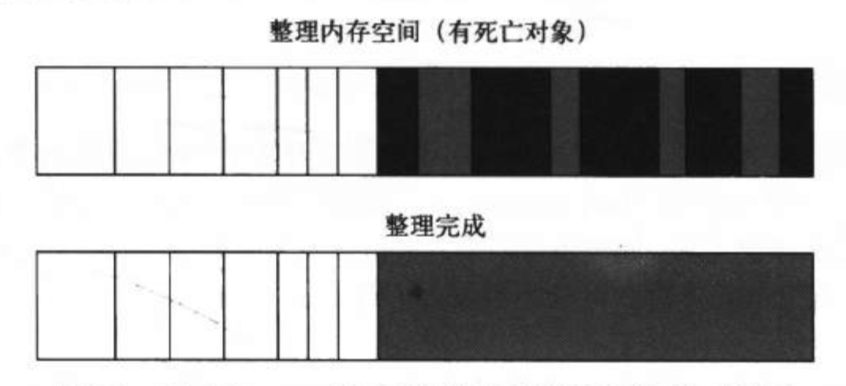
标记清除分为标记和清除两个步骤,先在老生代中遍历所有的对象,把那些在遍历过程中还活着的对象都加上一个标记,在下一步的时候那些没有被标记的对象就会自然的被回收了。示意图如下:

黑色的即为没有被标记已经死了对象,下一次就会被回收内存空间。
此种方式会导致下一次内存中产生大量碎片,即内存空间不连续,导致内存分配时面对大对象可能会无法满足,提前出发下一次的垃圾回收机制。所以便又有了一种标记-整理的方式。
对比标记-清除,他多了异步整理的过程,即把标记为存活的兑现统统整理到内存的一端,完成整理之后直接清除掉另一端连续的死亡对象空间,如下:
最后,由于标记-整理这种方式设计大量移动对象操作,导致速度非常慢,多以 V8 主要使用标记-清除的方式,当老生代空间中不足以为新生代晋升过来的顽固派们分配空间的时候,才使用标记-整理
V8的优化
由于在进行垃圾回收的时候会导致应用逻辑陷入全停顿的状态,在进行老生代的回收时,V8引入了 增量式标记,增量式整理,延迟清理等策略,中心思想就是为了能让一次垃圾回收过程不那么占用太长的应用程序停顿时间,而提出类似于时间片轮转一样的策略,让整个过程“雨露均沾”,GC弄一会,应用程序执行一会。
堆内内存与堆外内存
使用process.memoryUsage()可以查看node进程的内存使用情况。单位是字节
1 | { rss: 22233088, |
其中 rss 就是 node 进程的常驻内存。V8对内存有限制,但是不同于浏览器,Node在服务端难免会操作大文件流,所以有了一种跳脱 V8 的内存限制方式就是使用 buffer 进行堆外内存分配。如下代码:
1 | let showMem = () => { |
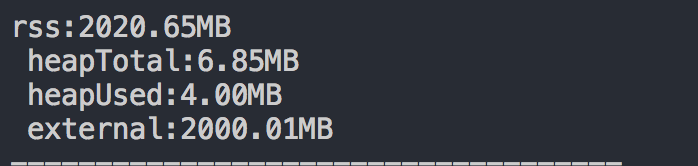
下面为分别调用 useMem()和useMemBuffer() 使用数组是通过V8分配堆内存,使用 Buffer 是不使用V8分配堆外内存,分别打印:
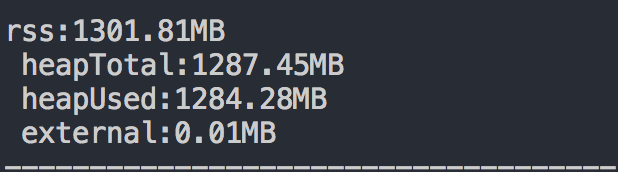
上图一表示堆内内存在一定循环次数之后达到溢出边缘,
图二可见,external和rss在不断增大但是其值早就突破了V8的内存上限。是因为堆外内存并不是V8进行内存分配的。
下一篇所要讨论的缓存算法中,缓存就是一个有可能造成内存泄漏的场景。
此外,在Node的模块机制当中,模块是要先通过编译,然后就会被缓存起来,那么此时模块必然是属于老生代空间的。如果像下面的代码一样:
1 | let arr = [] |
如果此时在响应请求中不断地调用这个模块导出的函数,那么 arr 中就会堆积大量的元素,有可能导致内存泄漏。
参考:
《深入浅出NodeJS》– 朴灵
本文为原创文章作为学习交流笔记,如有错误请您评论指教
转载请注明来源:https://isliulei.com/article/Node的GC/